
XPATH 가이드
Xpath는 XML DOM문서의 내용을 조회하는데 있어서 일관적이고 빠른 방법을 제공한다. 하지만, 사용하는 방법에 따라 성능상의 차이가 나타날 수 있다. 이 글은 JavaScript에서 Xpath를 활용하는데 있어 방법에 따른 성능의 차이를 보이고, 보다 효과적으로 XML DOM 문서 다루는 방법을 설명한다.
Xpath사용시 흔한 잘못
Xpath는 XML DOM(Document Object Model) 문서에서 특정 조건을 만족하는 노드를 찾는 표준적인 방법을 제공한다. 보통 하나의 노드를 찾고, 다시 부모를 찾거나 혹은 얻어진 값으로 다시 다른 Xpath 쿼리를 작성하는 경우가 많다. selectSingleNode() 혹은 selectNodes()등을 자주 호출하여 성능이 저하되고, 작성된 코드도 길어진다. Xpath의 조건을 잘 이용하면, 여러 번에 나누어 조회하지 않고 한번에 원하는 노드를 찾을 수 있는 경우가 많다.
|
<?xml version="1.0" encoding="euc-kr"?> <Message xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <Header/> <Body Desc="고객조회"> <LastName>김</LastName> <FirstName>철수</FirstName> <SSN>701202-1111111</SSN> <Rgn>02</Rgn> <Age/> <JobCode/> <Sex/> <CrdtRate Code="C10"> <Lov Code="C40" Desc="프리미엄"/> <Lov Code="C30" Desc="최우수"/> <Lov Code="C20" Desc="우수고객"/> <Lov Code="C10" Desc="단골고객"/> </CrdtRate> <Child SSN="001202-2024433"/> <Family> <LastName>김</LastName> <FirstName>영희</FirstName> <SSN>701202-2111111</SSN> <Sex>2</Sex> <RelCode>03</RelCode> </Family> <Family> <LastName>김</LastName> <FirstName>란아</FirstName> <SSN>001202-1111111</SSN> <Sex>1</Sex> <RelCode>04</RelCode> </Family> </Body> </Message> |
[예제 XML. sample_message.xml]
위의 XML 문서는 예제를 위한 테스트 문서 이다. 조회의 조건과 결과로 얻고 싶은 노드를 잘 구분하는 것이 좋다. 다음 세 개의 Xpath 문장은 비슷하지만, 리턴 하는 노드가 다르다.
/Message/Body/Family/SSN[.="001202-2024433"] // SSN 노드를 리턴/Message/Body/Family[SSN="001202-2024433"] // Family 노드를 리턴/Message/Body[Family/SSN="001202-2024433"] // Body 노드를 리턴
XML 문서가 가진 노드의 특정한 값을 찾고, 그 값으로 다른 노드를 검색하고자 하는 경우가 있다. 예를 들어, 위 XML 문서에서 /Message/Body/Child 의 SSN(주민번호)가 Family/SSN 값과 같은 Family 노드를 찾고자 한다면, 다음과 같이 쿼리를 작성할 수 있다.
/Message/Body/Family[SSN=string(/Message/Body/Child/@SSN)]
이와 같이 쿼리를 잘 작성하면 두 번 이상 조회를 한번에 하도록 할 수 있다. 다음 예는 의도적으로 selectNodes()를 사용하여 두개의 노드를 한번에 얻도록 쿼리를 작성한 것이다. /Message/Body/Child 노드의 SSN(주민번호)값과 같은 SSN 속성을 가지는 Family노드를 찾아 LastName과 FirstName 노드의 text를 얻는 코드이다. (xpath_01.htm 참조)
var xpath = '/Message/Body/Family[SSN
=string(/Message/Body/Child/@SSN)]/LastName
| /Message/Body/Family[SSN=string(/Message/Body/Child/@SSN)]
/FirstName';
var nodes = xmldoc.selectNodes(xpath);
var name = nodes[0].text + nodes[1].text;
alert(name);
Xpath 성능향상
Xpath 역시 쿼리조건을 기술하는 방법과 사용하는 방법에 따라 많은 성능의 차이를 보인다. 가장 좋은 방법은 쿼리 회수 자체를 줄이는 것이며, 두번째는 쿼리의 대상이 되는 범위를 줄이는 것이다. 다양한 비교를 통해 성능 향상을 위한 구체적인 방법을 살펴보자. 이 글에서 사용한 예제 XML은 아래의 [sample_message.xml]이다.
|
<?xml version="1.0" encoding="euc-kr"?> <!-- sample xml --> <message xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <header svr-time="20050505101023" ch="EnRich001" trans="E833CDF563EAC3" cli-time="20050101175941"> <svc name="CustInfo" mtd="getEmno_1" resid="getEmno_1"/> <scr comp-id="Btn02" no="0321"/> <cli ip="10.15.56.56" mac="00-90-96-75-C4-79"/> <user name="홍길동" id="plusjune"/> <res err-code="000">정상</res> <curr-odr>1</curr-odr> <debug log-level="1" test="true"/> <sso-token>Vy3zFySSOx2DTESTzTyGIDx2D1zCy1120</sso-token> </header> <sub-header> <auth>0</auth> <emp-no>17874</emp-no> <name>김유신</name> <br-cd>868</br-cd> <br-name>고객사업부</br-name> <level>4</level> <pos-cd>314</pos-cd> <pos-name>과장</pos-name> <!--중략 --> <cif>123456789</cif> <SSN/> </sub-header> <body> <result-set resid="cust_Info_select_detail_info"> <res resid="cust_workcarrer" code="0" msg=""> <rec rownum="1"> <col name="emno" type="char">9102321</col> <col name="gaze_stymd" type="date"/> <col name="gaze_edymd" type="date"/> <col name="position" type="number"/> <col name="branch_1" type="char"/> </rec> </res> <res resid="cust_license" code="0" msg=""> <rec rownum="1"> <col name="emno" type="char">9102321</col> <col name="qual_nm" type="char"/> <col name="gain_ymd" type="date"/> <col name="iss_plac" type="char"/> </rec> </res> <res resid="cust_traning" code="0" msg=""> <rec rownum="1"> <col name="emno" type="char">9102321</col> <col name="trn_nm" type="char"/> <col name="mng_plac" type="char"/> <col name="stday" type="date"/> <col name="enday" type="date"/> </rec> <!--중략 --> </res> </result-set> <result-set resid="product_info"> <cust id="cust_selfvaluation1" code="0" msg=""> <opt key="emno" type="char">9102321</opt> <opt key="yy" type="char">2005</opt> <opt key="hfy_clcd" type="char">1</opt> <opt key="branch_2" type="char"/> <opt key="apr_grp_nm" type="char"/> <opt key="rank" type="number"/> </cust> <!--중략 --> </result-set> </body> </message> |
시간 측정을 위해 LapTime.js 클래스(첨부파일 참조)를 사용하였다.
성능향상 – ‘//’를 쓰지 말 것
‘//’로 시작하는 쿼리는 XML DOM전체를 full-scan하기 때문에 좋지 않은 성능을 보여준다. [sample01.js]의 예제는 ‘//’를 쓴 경우와 절대 경로를 쓴 경우를 비교하고 있다. [sample01.js]의 코드에서 각각의 함수는 다음과 같은 내용을 가지고 있다.
-
- f1() – ‘//’로 시작하는 쿼리를 사용하였다.
- f2() – 먼저 부모노드를 찾고 그 다음 하위노드를 찾아 비교하였다.
- f3() – 절대 경로를 사용하였다.
[sample01.js]
function f1()
{
return xmldoc.selectSingleNode("//rec[@rownum='2']/col[@name='emno']").text;
}
function f2()
{
var node = xmldoc.selectSingleNode("//rec[@rownum='2']");
return node.selectSingleNode("col[@name='emno']").text;
}
function f3()
{
var base_path = "/message/body/result-set/res";
return xmldoc.selectSingleNode(base_path + "/rec[@rownum='2']/col[@name='emno']").text;
}
f1은 두 개의 조건을 한번에 사용하였고, f2()는 한 개의 조건에 해당하는 노드를 찾은뒤 다시 하위 노드에서 두번째 조건을 사용하였다. f3()는 절대경로를 사용하였다. [그림1]은 f1()~ f3()함수를 각각 10,000씩 수행하는데 걸린 수행 시간을 보여주고 있다.
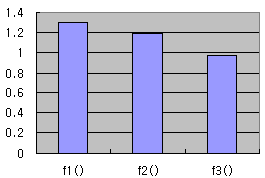
[그림1 – sample01.js 결과]
결과적으로 ‘//’로 시작하는 쿼리보다 절대 경로를 사용한 쿼리가 빠르다는 것을 알 수 있다. 이 차이는 XML DOM 문서가 크면 클수록 차이가 크게 생긴다.
성능향상 - 쿼리대상의 범위를 줄일 것
절대 경로를 사용하더라도 사용하는 횟수가 많으면 좋지 않은 성능을 가져올 수 있다. 매번 절대경로를 사용하는 것보다, 조회할 하위 노드 부분이 정해지면 상위 노드를 한번 찾아놓고, 하위 노드를 찾는 방식이 빠르다. 또한 특정 범위의 상위 노드를 처음 참조할 때 한번 찾아놓고, 다음 부터는 찾아놓은 노드를 활용하는 것도 성능 향상을 위해 좋은 방법이 될 수 있다.
[sample02.js]
function header1()
{
var result_text = '';
result_text += "name=" + xmldoc.selectSingleNode("/message/header/svc/@name").nodeValue + ",";
result_text += "mtd=" + xmldoc.selectSingleNode("/message/header/svc/@mtd").nodeValue + ",";
result_text += "resid=" + xmldoc.selectSingleNode("/message/header/svc/@resid").nodeValue + ",";
return result_text;
}
function header2()
{
var result_text = '';
var attrs = xmldoc.selectSingleNode("/message/header/svc").attributes;
result_text += "name=" + attrs.getNamedItem("name").nodeValue + ",";
result_text += "mtd=" + attrs.getNamedItem("mtd").nodeValue + ",";
result_text += "resid=" + attrs.getNamedItem("resid").nodeValue + ",";
return result_text;
}
function header3()
{
var result_text = '';
if(header3.attrs == undefined)
header3.attrs = xmldoc.selectSingleNode("/message/header/svc").attributes;
result_text += "name=" + header3.attrs.getNamedItem("name").nodeValue + ",";
result_text += "mtd=" + header3.attrs.getNamedItem("mtd").nodeValue + ",";
result_text += "resid=" + header3.attrs.getNamedItem("resid").nodeValue + ",";
return result_text;
}
[sample02.js]는 header1()과 header2(),header3() 함수로 구성되어 있다. header1()은 매번 절대 경로를 사용하여 속성값을 얻오는 것을 보여주고 있고, header2()함수는 부모 노드를 찾은 뒤 노드의 함수들을 이용하여 하위 노드(혹은 속성)값을 가져오는 방법을 보여준다.
header3()은 조금 더 진보한 방법을 사용하고 있다. 처음에 속성 노드를 찾아 놓고 JavaScript에 멤버를 추가하여 유지하도록 하는 방식(header3.attrs는 Java 혹은 C#의 static 멤버와 같다. 이와 관련하여 Object Oriented JavaScript (2)를 참조하라)을 사용하고 있다. 반복하여 호출하는 경우 즉, XML노드를 반복하여 참조하는 경우에 매우 유리하다. header1()과 header2(),header3() 함수의 수행속도를 비교한 결과는 아래 [그림2]와 같다.
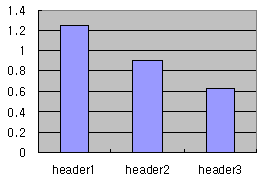
[그림2 – sample01.js 결과]
성능향상 – 객체지향 JavaScript와 BOM 활용
JavaScript의 객체지향을 잘 이용하여 BOM(Business Object Model)을 생성하고 활용하면, 속도의 개선 뿐만 아니라 어플리케이션의 구성을 유지보수하기 좋은 형태로 구성할 수 있다. 앞서 이야기한 것과 같이 Xpath를 이용하여 XML DOM을 매번 조회하지 않고, 초기에 한번만 조회하도록 하였다. header1()과 header2()는 그러한 차이를 보여준다.
function header1(){
this.getResultText = function _getResultText(){
var result_text = '';
var node = xmldoc.selectSingleNode("message/header/svc");
result_text += "name=" + node.attributes.getNamedItem("name").nodeValue + ",";
result_text += "mtd=" + node.attributes.getNamedItem("mtd").nodeValue + ",";
result_text += "resid=" + node.attributes.getNamedItem("resid").nodeValue + ",";
return result_text;
}
}function header2(){
var result_text;
this.update = function _update(){
var node = xmldoc.selectSingleNode("message/header/svc");
result_text += "name=" + node.attributes.getNamedItem("name").nodeValue + ",";
result_text += "mtd=" + node.attributes.getNamedItem("mtd").nodeValue + ",";
result_text += "resid=" + node.attributes.getNamedItem("resid").nodeValue + ",";
}
this.getResultText = function _getResultText(){
if(result_text == undefined)
this.update();
return result_text;
}
}
[sample03.js]
header2()는 두개의 멤버함수를 가지고 있다. getResultText()는 결과 값을 DOM으로부터 가져와 result_text에 기록하는 역할을 수행한다. 즉, DOM에 대한 Xpath 쿼리를 수행한다. 아래의 코드는 결과가 정의되어 있지 않을 때(undefined) Xpath 쿼리를 수행하도록 하고 있다.
if(result_text == undefined) this.update();
update() 멤버함수는 필요에 따라 호출될 수 있다. (예를 들어 XML DOM을 새로 읽었거나 변경된 경우). 이런 구성을 잘 활용하면, 속도의 증진 뿐만 아니라 복잡한 XML DOM과 템소를 Wrapping 하여 유지보수하기 좋고 이해하기 좋은 구성을 가지도록 코드를 작성할 수 있다. [그림3]은 반복하여 수행한 결과를 보여준다. (header2의 경우 Xpath 쿼리를 1회만 수행하므로, 반복적으로 Xpath 쿼리를 수행하는 header1에 비해 비교가 되지 않을 정도로 빠르다)
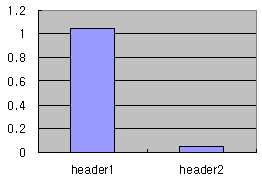
결론
Xpath 쿼리를 잘 작성하면, 여러 번에 나누어 쿼리하지 않아도 되므로 코드를 간결하게 유지할 수 있을 뿐만 아니라, 잦은 쿼리의 부하도 줄일 수 있다. XML DOM을 효과적으로 다루는 첫번째 방법은 쿼리회수 자체를 줄이는 것이고, 두번째는 검색 대상 범위를 줄이는 것이다. DOM 전체를 크게 몇 개의 논리적인 단위로 나누고, 각각의 상위 노드에 대한 참조를 가지고, 그 참조에 대해 Xpath 쿼리를 하는 것도 하나의 방법이다. 또한, BOM을 잘 구성하여 Xpath와 관련된 operation을 wrapping 함으로써, 속도의 개선뿐만 아니라 유지보수하기 좋도록 어플리케이션을 구성할 수 있다.
'Publisher > XML/XHTML' 카테고리의 다른 글
| XML 메소드와 속성 및 특성 (0) | 2008.04.15 |
|---|